

Synthetic data generation grounded in real data sources

Introduction
In this blog, we explore the paper on Source2Synth, a framework for synthetic data generation. Source2Synth addresses the common issues of low-quality synthetic data by grounding it in real-world sources and employing a multi-stage curation process. This approach enhances data quality and relevance.
What is the problem with synthetic data generation?
LLMs have impressive capabilities in generating human-like text, but LLMs struggle with complex tasks like structured data processing, multi-step reasoning, and tool usage. Synthetic data generation with existing frameworks often produces low-quality data points that lack sufficient reasoning steps and are not grounded in real-world sources, leading to poor dataset quality and performance.
Existing ways of synthetic data generation
The existing ways of synthetic data generation using LLMs involve several strategies:
- Prompting LLMs: Some approaches probe the knowledge in LLMs by providing a prompt and allowing the model to either generate the continuation of a prefix or predict missing words in a close-style template.
- Quality improvement: Other approaches aim to enhance synthetic data quality using model-based or human-driven filtering.
- Real-world data use: Some recent works leverage real-world data, such as web corpora or open-source code snippets, to construct high-quality synthetic data.
- Back-translation or initial fine-tuning: Certain approaches use techniques like back-translation or initial fine-tuning to generate seeds for synthetic data generation.
What is Source2Synth?
Source2Synth is a method for generating synthetic data grounded in real-world sources aimed at improving realism, diversity, and factual accuracy. It works in three stages: Dataset generation (selecting a data source and generating task-specific examples), Dataset curation (filtering and imputation to enhance data quality), and Model fine-tuning (using curated data for final model training). It improves performance in complex tasks like tabular question answering and multi-hop reasoning without relying on human annotations.
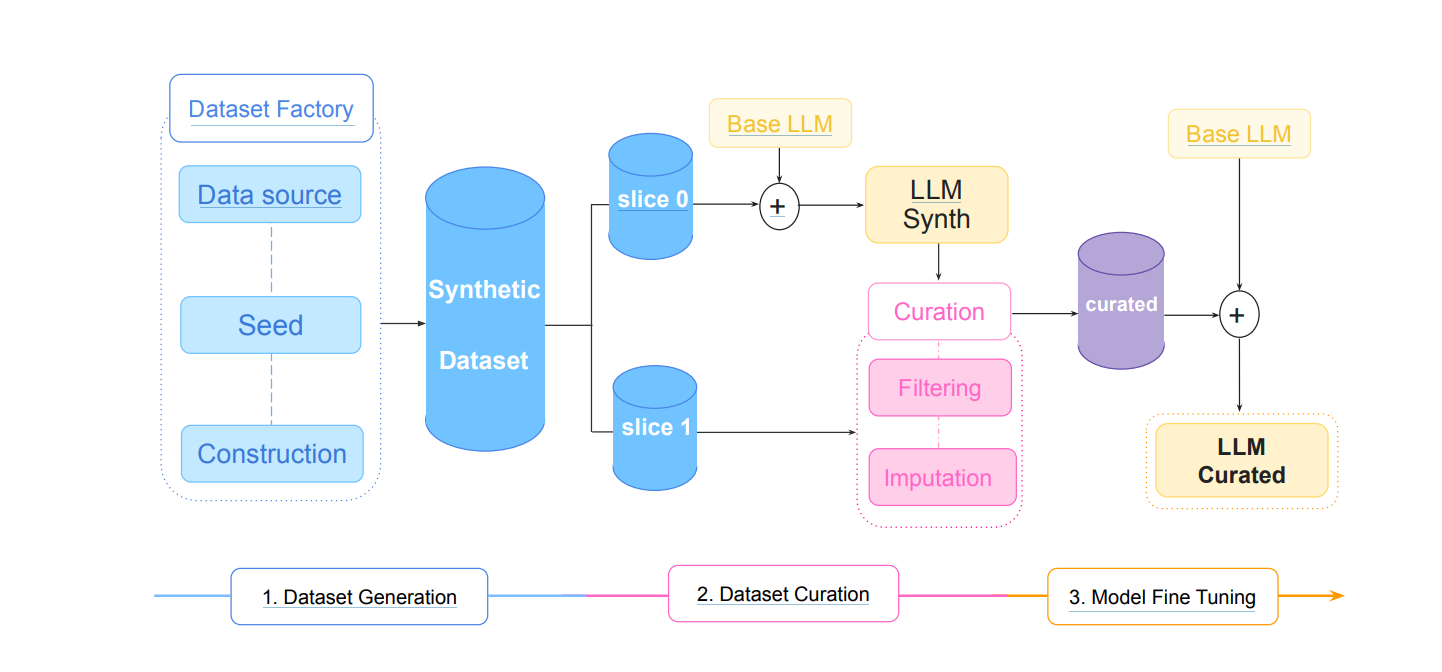
The Source2Synth framework generates high-quality synthetic data for fine-tuning LLMs by grounding it in real-world external data sources. It consists of three stages: Dataset generation, Dataset curation, and Model fine-tuning. Below is a step-by-step explanation of each stage and its methodologies.
1. Dataset generation
a. Data source selection
The process begins with selecting a data source. This can be:
- An existing dataset repurposed for a specific task.
- A collection of data points that will be used to construct a new dataset.
- Structured information, such as graphs or tables.
Source2Synth does not require human annotations on these entries. Instead, it enriches the dataset with extra instructions, ensuring its adaptability for different tasks.
b. Seed generation
A seed is generated to initiate the creation of a synthetic dataset. The seed topic, selected based on a random portion of the source data, serves as the initial trigger for the generation process. This randomness ensures diversity in the output data.
The seed guides how the source data will be utilized and determines the structure of the dataset entries. This step is critical for ensuring variety and relevance in the synthetic data.
c. Dataset construction
Once the seed is generated, the synthetic data is constructed through a step-by-step process, leveraging a chain of reasoning approach. Inspired by the chain of thought prompting, this method breaks down complex tasks into smaller subtasks. Instructions are provided for combining these subtasks into a final output.
In this stage, the seed is used to build synthetic examples in a stepwise manner, and intermediate steps are generated. These steps are then used as supervision for training the LLM, providing a reasoning chain that guides the model in arriving at an answer for a given question.
2. Dataset curation
a. Model-based refinement
After generating the synthetic dataset, the Dataset Curation process refines it to improve quality. This is done without human supervision through a model-based approach. The dataset is sliced into two parts:
- Slice 1 is used to fine-tune the LLM (referred to as LLMSynth).
- Slice 2 is curated by the fine-tuned LLMSynth to filter and improve its quality.
b. Data filtering
LLMSynth generates predictions for each entry in the synthetic dataset, trying multiple times (k tries) to produce an accurate output. If the model fails to predict the correct output at least once, the entry is considered low quality and removed from the dataset. This ensures that only high-quality examples are retained.
c. Data imputation
During this stage, parts of the augmented data points are intentionally blanked, and the LLM is tasked with filling in the blanks. This imputation process helps clean up the data, removing unnatural or low-quality elements and making it more suitable for model fine-tuning.
The final output of the Dataset Curation stage is a clean, high-quality dataset that can be used for further model training.
3. Model fine-tuning
a. Fine-tuning the model
In the final stage, the model is fine-tuned on the curated synthetic dataset. The model can either be a base LLM or an instruction-tuned version of the LLM, depending on the task requirements.
The fine-tuning process focuses on supervised training, where both the reasoning chain and the final answer are used as targets. This allows the model to learn how to approach multi-step tasks and reason through complex problems in a structured manner.
b. Output: LLMCurated
The result of the fine-tuning process is a model called LLMCurated, which is optimized for performing the desired task, leveraging the high-quality, synthetically generated dataset. This model is now ready to tackle complex tasks that require step-by-step reasoning and accurate predictions.
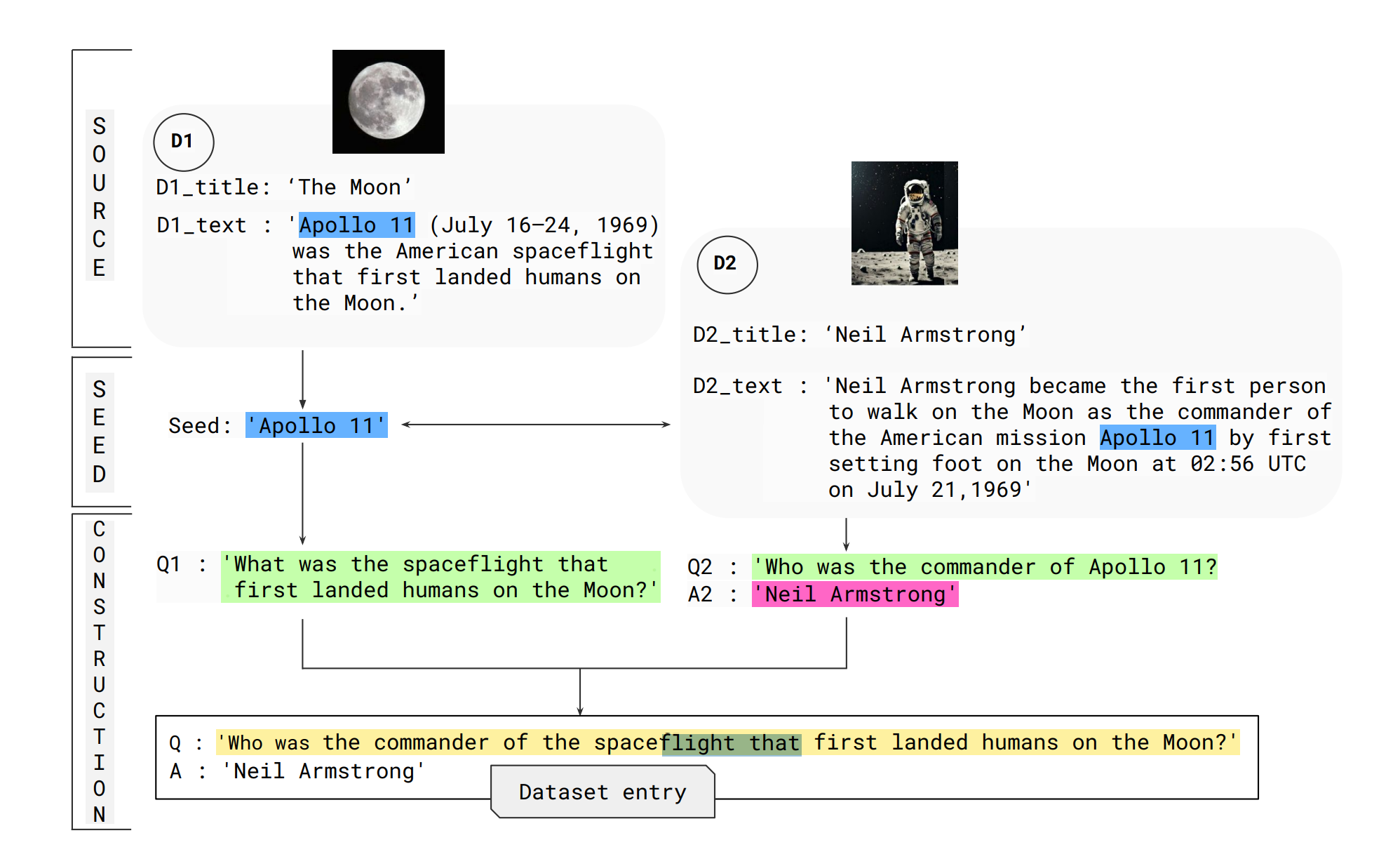
Experimental setup
The experimental setup for Source2Synth involved testing its performance on two distinct domains: multi-hop question answering (MHQA) and tabular question answering (TQA). For each domain, the generated synthetic data was curated and used for fine-tuning the model, with comparisons made against various baseline methods.
Multi-hop question answering (MHQA) setup
Source2Synth was evaluated on the HotPotQA benchmark, which consists of 113,000 multi-hop question-answer pairs based on Wikipedia articles. The test set included 7,405 examples evenly split between the bridge and comparison questions. Bridge questions, requiring reasoning across multiple documents, were prioritized for synthetic data generation due to their higher difficulty. Source2Synth generated 1,250 synthetic examples targeting bridge questions and incorporated an additional 500 comparison questions from the HotPotQA training set to balance the fine-tuning process.
Metrics: The primary evaluation metric was soft exact match (soft-EM), where a score of 1 was given if the generated answer contained the correct golden answer, otherwise 0.
Base model: The experiments were initialized from Llama-2 70B-Chat, with Source2Synth and baseline models fine-tuned from this base.
Baselines:
- Instruction-tuned LLM: Using Llama-2 70B-Chat in a zero-shot setting.
- Fine-tuned LLM (HotPotQA only): Fine-tuning on 500 examples from the HotPotQA training set.
- LLMSynth (synthetic dataset only): Training on 1,250 synthetic examples from the first data slice without any curation.
- LLMSynth (synthetic and HotPotQA): Training on a combination of uncurated synthetic data and 500 HotPotQA examples.
All models were evaluated using zero-shot and three-shot chain-of-thought (CoT) prompting methods.
Tabular question answering (TQA) setup
In the TQA domain, Source2Synth was tested on the WikiSQL dataset, which contains 80,654 examples of natural language questions, SQL queries, and their corresponding tables derived from 24,241 Wikipedia tables. After removing non-executable SQL tables, 7,857 examples were included in the validation split.
Metrics: Two evaluation metrics were used—exact match (EM) and soft-EM. EM equals 1 if the generated answer exactly matches the golden answer, while soft-EM allows for minor differences in formatting.
Base model: For TQA, the base model was Starchat-beta, a 16-billion parameter, instruction-tuned language model designed for coding assistance. This model was fine-tuned using 8,000 synthetic examples per slice (16,000 in total), with 2,160 examples retained after curation for fine-tuning.
Baselines:
- Zero-shot table QA: Providing only the task instruction, table, and question in a zero-shot format.
- One-shot, no context QA: Including a one-shot example (question and answer) without the table context, followed by the actual question.
- One-shot table QA: Providing a one-shot example with the table and actual question, accounting for context length limitations.
- One-shot table+SQL QA: This includes a table and question example, along with instructions suggesting the use of an SQL tool to retrieve the answer.
- LLMSynth: Fine-tuning on synthetic data without applying a data curation step.
Results
The experimental results for multi-hop question answering (MHQA) and tabular question answering (TQA) show the effectiveness of the Source2Synth pipeline for fine-tuning language models. For MHQA, models fine-tuned with the curated synthetic data (LLMCurated) consistently outperformed those using uncurated synthetic data (LLMSynth) or HotPotQA data alone.
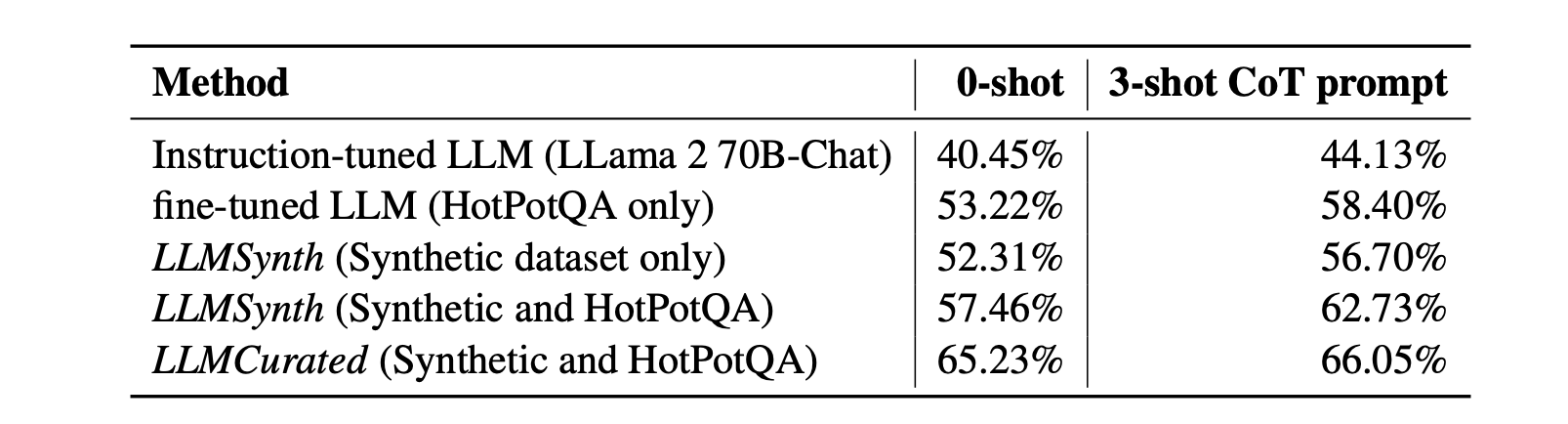
The LLMCurated model achieved the best performance, particularly on more complex bridge-type questions, where it showed a 17.44% improvement over the base instruction-tuned model. Scaling synthetic data also resulted in better performance, with more significant gains seen after the curation step.
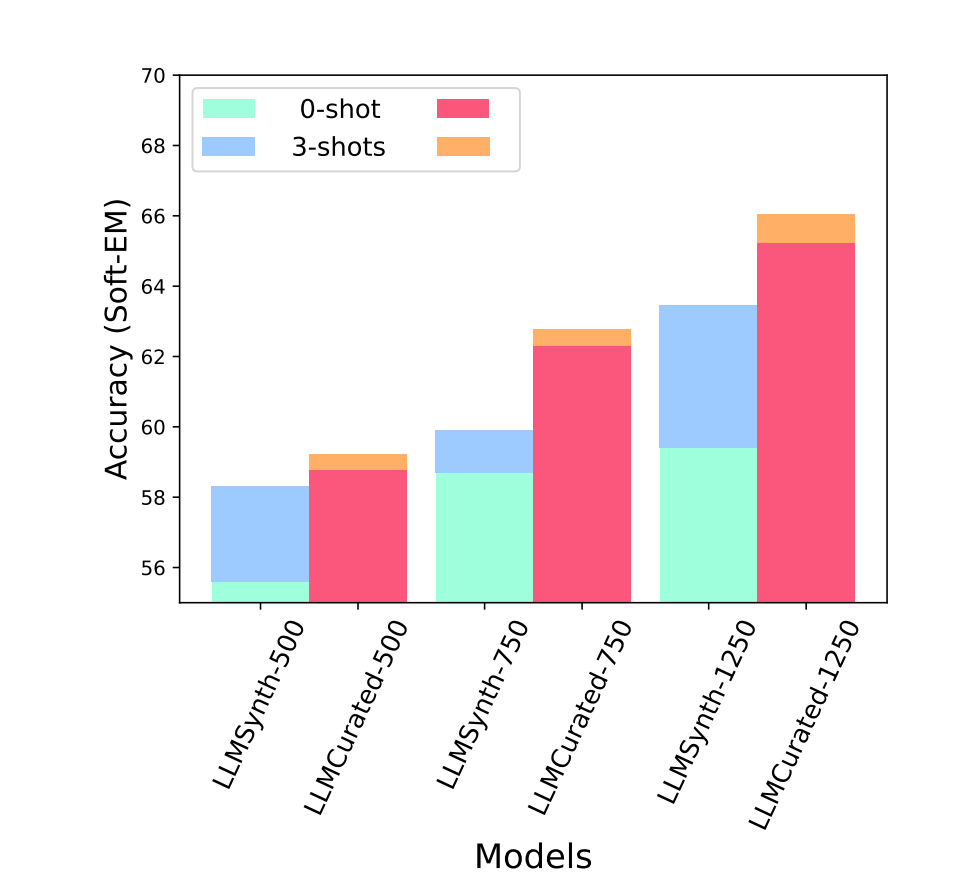
For TQA, using the WikiSQL dataset, the instruction-tuned StarChat model performed poorly without context (0.25% EM), and even when table context was provided, the improvement was minimal. However, fine-tuning with Source2Synth synthetic data drastically improved performance. The LLMCurated model achieved a 34.5% EM, compared to 23.86% for LLMSynth, demonstrating the value of the curation process in generating high-quality data for fine-tuning. Both tasks showed that synthetic data, especially when curated, enhances model performance significantly.

Conclusion
The Source2Synth framework advances synthetic data generation by grounding it in real-world sources and employing rigorous curation. Its multi-stage process—encompassing dataset generation, model refinement, and fine-tuning—produces high-quality data that boosts model performance on complex tasks like multi-hop and tabular question answering.
Results show that Source2Synth outperforms baseline models, significantly enhancing performance on both multi-hop and tabular tasks. By integrating real-world grounding with structured reasoning, Source2Synth sets a new benchmark for synthetic data quality and model fine-tuning.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim.


