

MiniCheck: Efficient fact-checking of LLMs on grounding documents
Introduction
In this blog, we’ll explore a research paper that tackles the challenge of grounding LLM outputs in evidence, which is crucial for tasks like retrieval-augmented generation and document-grounded dialogue. The paper introduces a cost-effective approach by creating smaller models that deliver GPT-4-level performance at a fraction of the expense. By generating synthetic training data with GPT-4, the authors train models to effectively verify facts and synthesize information. They present MiniCheck-FT5, which matches GPT-4’s accuracy while being significantly cheaper. We’ll explore the methods, results, and available resources, including the LLM-AGGREFACT benchmark and the new models.
Existing challenges of grounding LLM outputs in evidence
The existing challenges in fact-checking statements against grounding documents, especially in tasks like RAG and document-grounded dialogue, are:
- Accuracy in fact-checking: The system needs to correctly identify subtle errors in statements while avoiding high false positive rates, as most statements tend to be accurate.
- Efficiency: Verifying many facts in a single response can be computationally expensive. For example, checking dozens of facts in a response could lead to hundreds of entailment checks, significantly increasing the cost when using LLMs for self-verification. For instance, the 110-150 word biographies in FActScore contain 26-41 atomic facts that are checked against 5 documents each, resulting in 130-205 entailment checks.
- High computational cost: Using LLMs to verify each fact can lead to substantial costs, as a single response may require numerous checks against grounding documents, especially for retrieval-augmented content.
Solution
The research paper proposes solutions to the challenge of fact-checking grounding documents through the following key contributions:
Synthetic data generation methods: They develop two methods for generating synthetic training data that address the specific challenges of fact-checking across grounding documents. This helps the model learn how to simultaneously verify multiple facts in complex sentences, increasing its efficiency and accuracy.
New benchmark: They establish a new benchmark that unifies factual evaluation across both closed-book and grounded generation tasks. This provides a standardized framework for measuring performance in fact-checking and helps compare models across different scenarios.
MiniCheck system performance: The MiniCheck system demonstrates significant improvements over previous specialized systems, outperforming them by 4% to 10% in accuracy. Despite using less fine-tuning data, MiniCheck achieves performance on par with GPT-4, but with a much smaller model size, faster inference speed, and 400 times lower cost. Moreover, MiniCheck eliminates the need for a separate claim decomposition step, further enhancing its efficiency.
Synthetic data generation methods
To tackle these challenges, new data is necessary. Existing datasets like MNLI and ANLI lack the complexity needed for LLM fact-checking, and annotating real errors at scale is difficult. The aim is to create a dataset of N instances with documents (Di), claims (ci), and labels (yi ∈ {0, 1}) using two innovative synthetic data generation methods.
Method 1: Claim to doc generation (C2D)
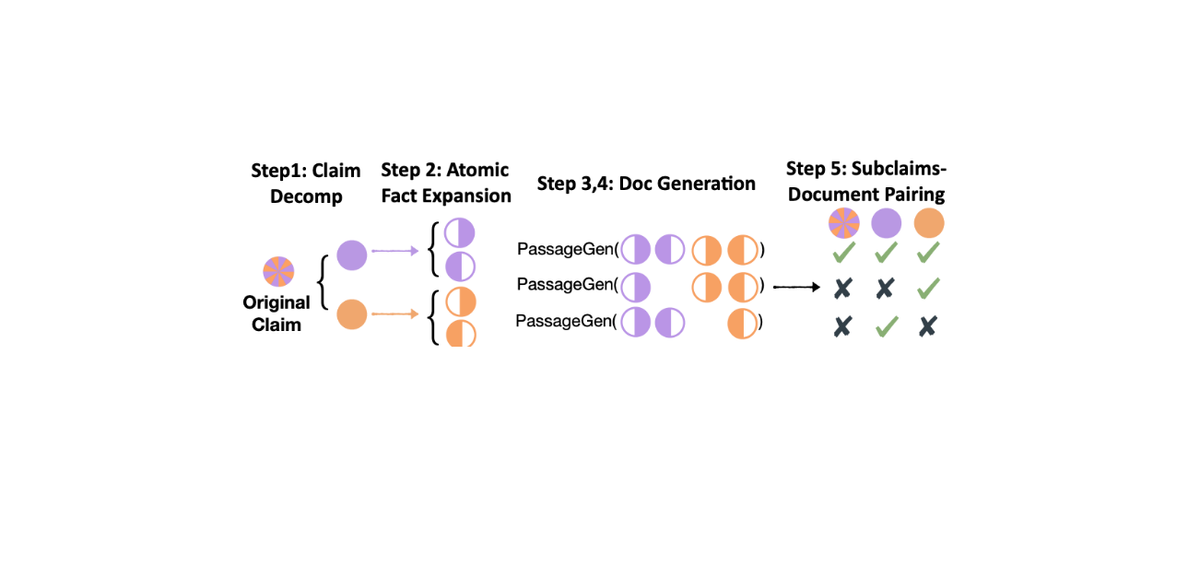
In the C2D method, it is assumed that a set of human-written claim statements is available. The objective is to create synthetic documents that challenge models to verify multiple facts in each claim against several sentences. Here’s a summary of the steps:
Step 1: Claim decomposition Decompose a claim into atomic facts using GPT-3.5. Given a claim ( c ), it is broken down into a set of atomic facts ( a ) using GPT-3.5, resulting in Decomp(c) = (a_1,......, a_l).
Example claim (c): "The company increased its revenue and expanded its product line."
Step 2: Atomic fact expansion For each atomic fact, generate two supporting sentences using GPT-4 with a 4-shot prompt. These sentences must be combined to support the fact.
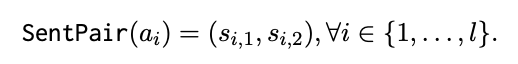
Example atomic facts (a):
- ( a_1 ): "The company increased its revenue."
- ( a_2 ): "The company expanded its product line."
Step 3: Supporting document generation Create a document that integrates all generated sentences using GPT-4. This document should provide evidence for the claim.
Example supporting tuple: (D, c, 1), meaning the document ( D ) supports the claim ( c ).
Step 4: Nonsupporting document generation Generate a second document by omitting one sentence from each sentence pair in the original document. Check if the claim is no longer supported by the modified document.
Example non-supporting tuple: (D′{a_i\j}, c, 0), meaning a modified document D′{a_i\j}, which lacks part of the evidence, does not support the claim ( c ).
Step 5: Pairing subclaims and documents Augment the data by creating subclaims from subsets of atomic facts. Pair these sub-claims with both supporting and nonsupporting documents to create a diverse set of examples. In this step, the goal is to augment the dataset by creating more examples using sub-claims and their relationships to the grounding documents. This involves:
- Generating subclaims: Creating subsets of atomic facts from a claim.
- Power(a) includes subsets like {a_1}, {a_2}, and {a_1, a_2}.
- Augmented subclaims (Aug(c)): Aug(c) includes subclaims like "The company increased its revenue" from {a_1} and "The company expanded its product line" from {a_2}.
- Pairing subclaims with documents: Checking how these subclaims are supported or not supported by the grounding documents.
- For subclaim {a_1}:
- Supporting: If the document ( D ) still supports the subclaim "The company increased its revenue" without ( a_2 ), we get (D, {Merge}{a_1}, 1).
- Non-Supporting: If a document ( D′{a_i\j} ) lacks support for ( a_1 ), we get (D′{a_i\j}, Merge{a_1}, 0).
- For subclaim {a_2}:
- Supporting: If the document ( D ) supports "The company expanded its product line" without ( a_1 ), we get (D, Merge {a_2}, 1).
- Non-supporting: If ( D′{a_i\j} ) lacks support for ( a_2 ), we get (D′{a_i\j}, Merge{a_2}, 0).
- For subclaim {a_1}:
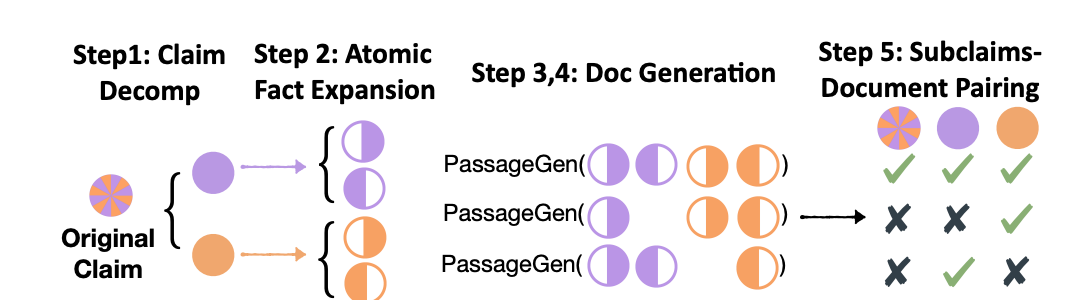
Method 2: Doc to claim generation (D2C)
The aim of the D2C method is to improve document diversity and realism compared to the C2D method, minimizing distribution shifts between synthetic training documents and real test documents. This involves using a set of human-written documents to generate claims and pair them with sections of these documents, requiring multi-sentence, multi-fact reasoning for validation.
Step 1: Chunk-level summarization
Human-written documents are divided into three chunks {D1, D2, D3}, each roughly equal in length. GPT-4 is used to generate a summary sentence for each chunk, resulting in a set of summary sentences {c1, c2, c3}. These summaries are assumed to be factually consistent with their corresponding chunks.
Step 2: Claim decomposition and subclaim augmentation
Each summary sentence ci is decomposed into atomic facts ai = {ai,1, ..., ai,l}. Augmented subclaims are then created by merging subsets of these atomic facts, resulting in Aug(ci) = Merge(a′i) : ∀a′i ∈ Power(ai).
Step 3: Document-claim augmentation
For each chunk Di = Concat(s), where s = {si,1, ..., si,n}, new documents are created by iteratively removing each sentence si,j. The entailment label for each atomic fact ai,k in ci is determined based on the modified document D′i\j. If all atomic facts are supported in the modified document, tuples (D′i\j, Merge(a′i), 1) are created; otherwise, tuples D′i\j, Merge(a′i), 0 are generated.
Step 4: Cross-document-claim augmentation
Documents are further augmented by using chunks Dj (where j ≠ i) to support or refute the claims ci and their atomic facts ai. The entailment label for each atomic fact ai,k in ci is evaluated using chunk Dj. Tuples (Dj, Merge(a′i), 1) or (Dj, Merge(a′i), 0) are created based on whether the atomic facts are supported or refuted by the other chunks.
New benchmark: LLM-AGGREFACT benchmark
LLM-AGGREFACT is a fact verification benchmark that aggregates 10 recent, publicly available datasets focused on factual consistency in both closed-book and grounded generation settings.
Characteristics:
The benchmark includes human-annotated (document, claim, label) tuples from diverse sources, such as Wikipedia, interviews, and web text, spanning domains like news, science, and healthcare. Most claims are generated by recent models, with minimal human intervention.
Datasets overview:
The benchmark features datasets like CLAIMVERIFY, EXPERTQA, FACTCHECK-GPT, and others.
Benchmark details:
- Validation/test set split: For AGGREFACT, TOFUEVAL, WICE, and CLAIMVERIFY, the existing validation and test splits are used. For REVEAL, FACTCHECK-GPT, EXPERTQA, and LFQA, the data is randomly divided (50%/50%) to ensure unique query responses do not overlap.
- Evaluation metric: Balanced accuracy (BAcc) is used to assess performance:
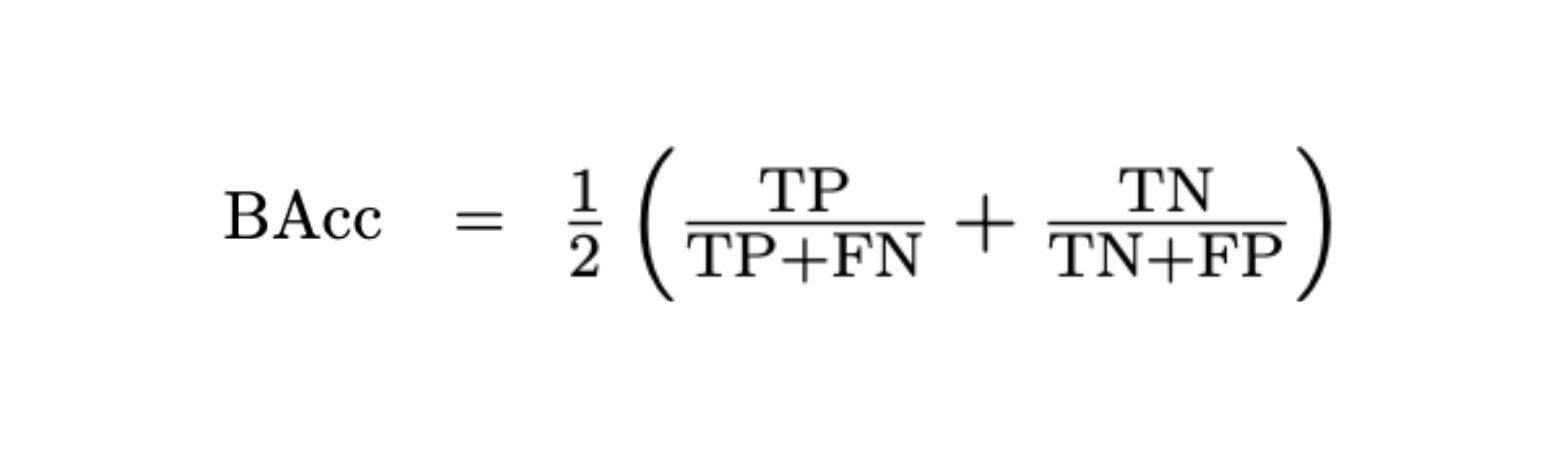
MINICHECK models
Three models are fine-tuned using synthetic data and cross-entropy loss.
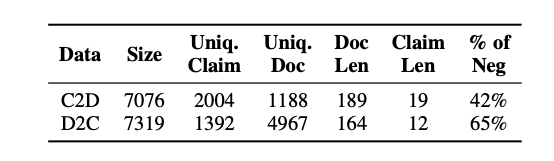
MiniCheck-DBTA and MiniCheck-FT5
Models trained on the ANLI dataset show strong performance. For fine-tuning, deberta-v3-large and flan-t5-large are used. A subset of 21K examples from ANLI, where previous models made errors, is combined with 14K synthetic examples, resulting in 35K training data points. Labels from ANLI, "contradiction" and "neutral," are mapped to "unsupported."
MiniCheck-RBTA
To improve on the AlignScore system, roberta-large is fine-tuned with a binary classification head on 14K synthetic data points.
Experimental setup
The study evaluates the following specialized fact-checkers: T5-NLI-Mixed, DAE, QAFactEval, SummaC-ZS, SummaC-CV, AlignScore, and FT5-ANLI-L, which fine-tunes flan-t5-large on the ANLI dataset.
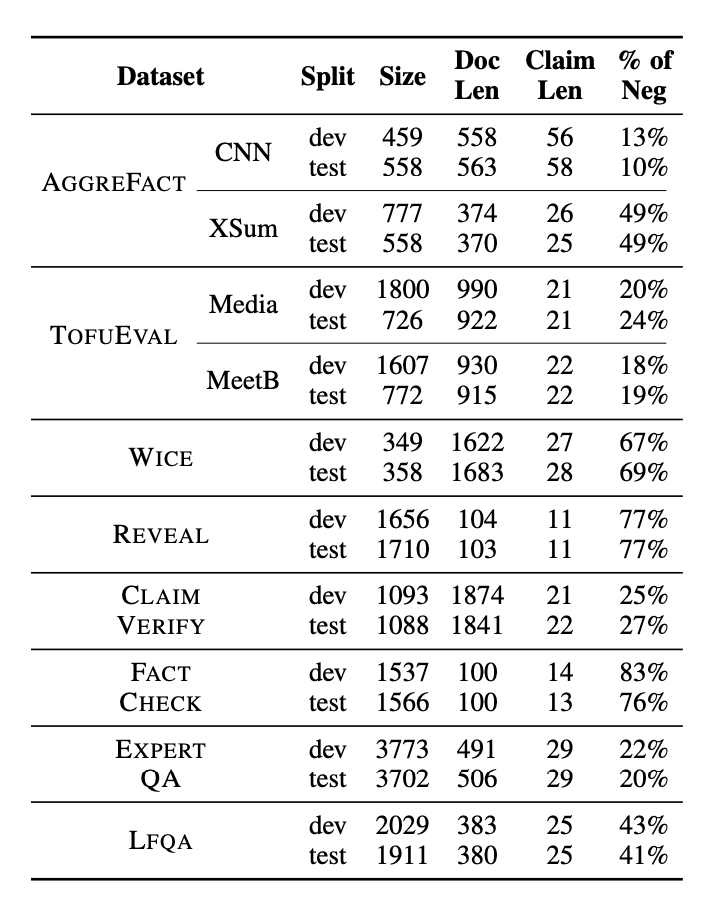
Statistics of datasets in LLM-AGGREFACT. The size of datasets, the average length of documents and claims, and the proportion of unsupported claims.
LLMs tested include Gemini-Pro, PaLM2-Bison, Mistral8x7B, Mistral-Large, Claude 2.1, Claude 3 Opus, GPT-3.5, and GPT-4.

Results
Synthetic data enhances performance across various models. MiniCheck-FT5 shows a 4.3% improvement over AlignScore, surpassing it on 6 out of 10 datasets. While larger models like MiniCheck-FT5 offer gains, size alone doesn’t ensure better performance, as shown by T5-NLI-Mixed and FT5-ANLI-L. MiniCheck models achieve competitive results compared to top LLM-based fact-checkers. MiniCheck-FT5 performs similarly to GPT-4 but is more efficient. See Table 2 for performance metrics.
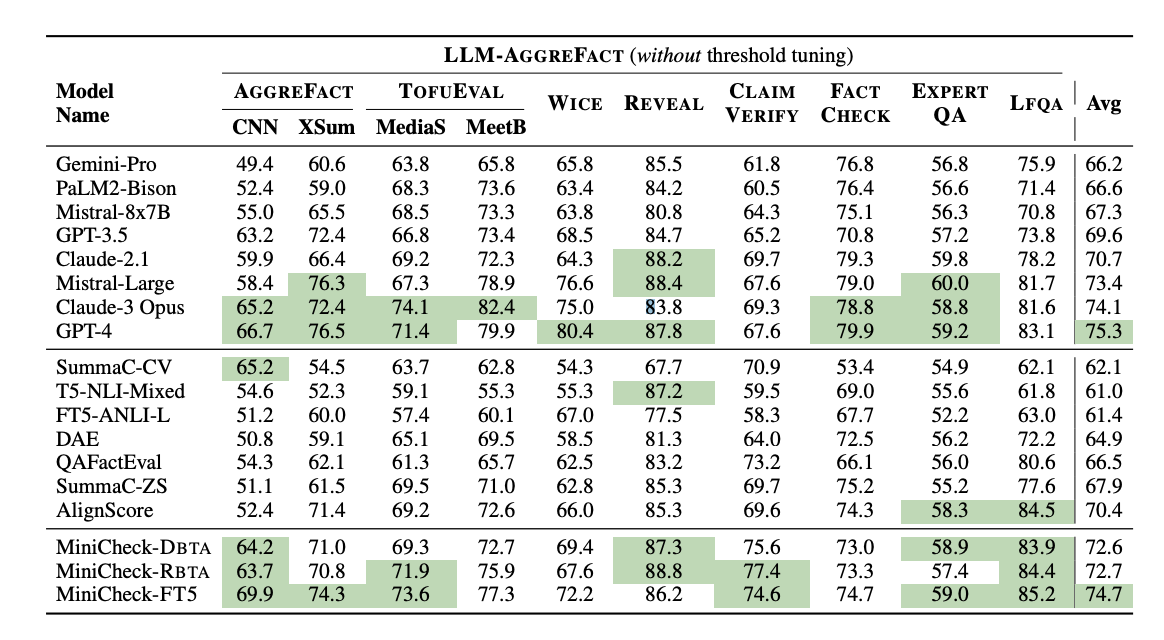
Specialized fact-checkers generally incur lower inference costs than LLMs. For instance, MiniCheck-FT5 matches GPT-4's performance but is over 400 times cheaper. Detailed cost comparisons are provided in Tables 3 and 4
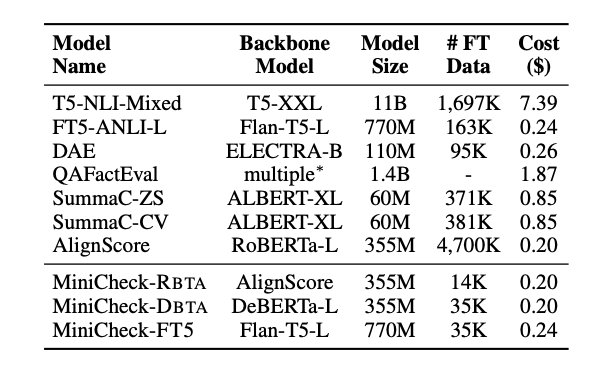
Conclusion
This research paper presents a significant advancement in grounding LLM outputs through the introduction of MiniCheck-FT5, a cost-effective model that matches GPT-4’s accuracy while dramatically reducing expenses. By leveraging synthetic training data generated through innovative methods, the study addresses the challenges of accuracy, efficiency, and high computational costs in fact-checking. The new MiniCheck models and the LLM-AGGREFACT benchmark offer valuable tools for evaluating and improving fact-checking performance in various settings.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim.