

Chain-of-Thought prompting: A guide to enhancing LLM reasoning

Introduction
This blog explores Chain-of-Thought (CoT) prompting as a powerful technique for enhancing reasoning in large language models. By guiding models to break tasks into smaller steps, CoT mirrors human problem-solving. A study on shift ciphers reveals that CoT reasoning is influenced by factors such as task probability, frequency in pre-training, and reasoning complexity. CoT combines probabilistic reasoning and memorization, leading to what is termed "noisy reasoning." As model scale increases, CoT enables LLMs to tackle more complex tasks, broadening the scope of language-based reasoning approaches.
What is Chain-of-Thought prompting?
At its core, Chain-of-Thought prompting enhances the problem-solving abilities of LLMs. Instead of expecting a model to arrive at an answer directly, CoT prompting guides the model to break down a complex task into smaller, intermediate reasoning steps. This mirrors how humans solve problems—step by step.
Take a simple math word problem as an example:
Roger has 5 tennis balls. He buys 2 more cans of tennis balls, each with 3 balls. How many balls does he have now?
Without CoT prompting, a model might provide the correct answer without explaining how it arrived. CoT prompting, on the other hand, encourages the model to provide a step-by-step breakdown, such as:
Roger starts with 5 balls. He buys 2 cans, each containing 3 balls. That gives him 6 more balls. 5 + 6 equals 11.
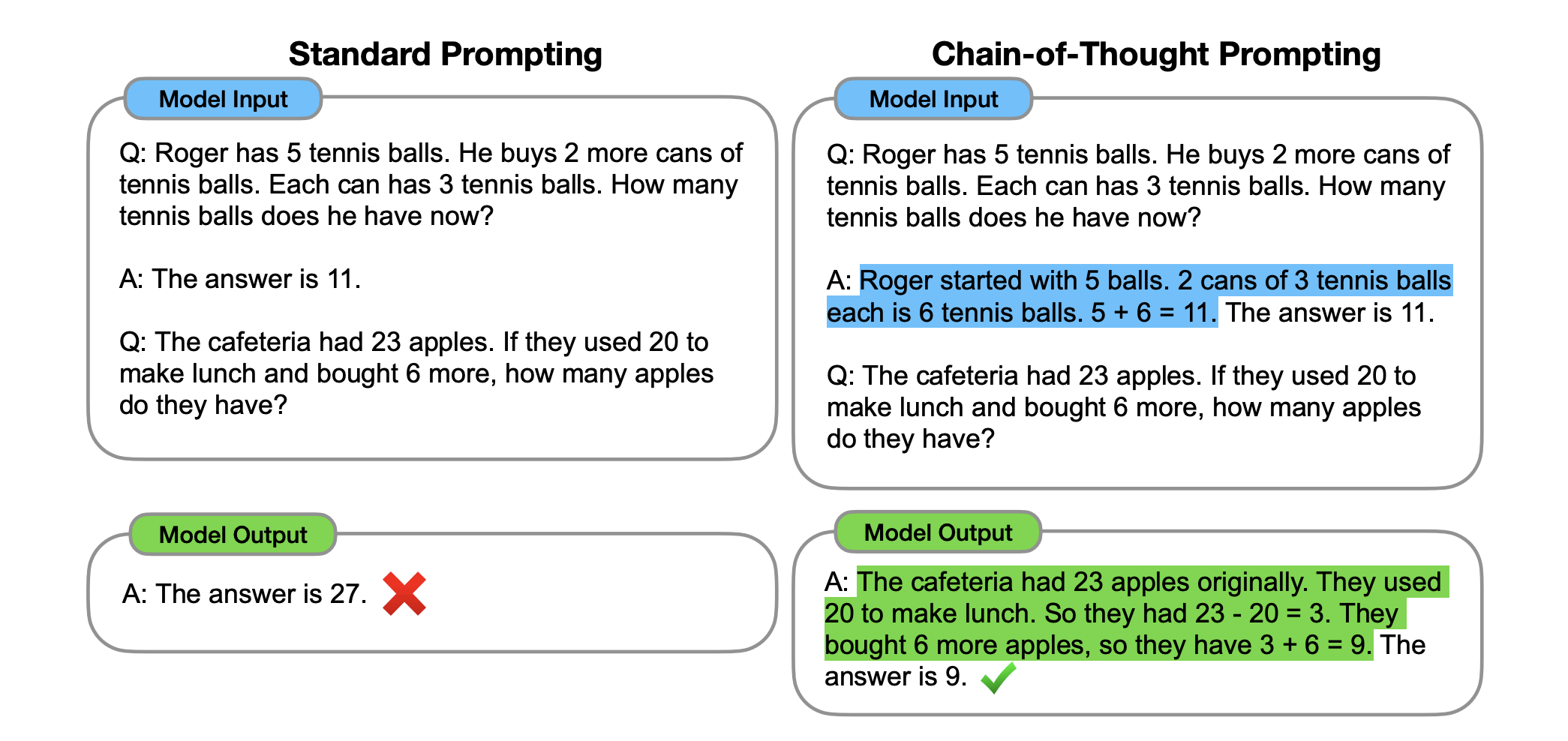
This stepwise process not only improves the model’s accuracy but also makes the reasoning behind its answers more interpretable.
Why Chain-of-Thought prompting works?
CoT prompting succeeds for several reasons:
- Decomposition of complex problems: By breaking a problem into smaller parts, CoT allows models to allocate more computational resources to individual steps, leading to better overall performance. This is especially helpful in tasks that require multiple steps of reasoning, such as solving multi-step math problems or answering questions that involve multiple concepts.
- Interpretable reasoning: With CoT prompting, we gain a window into the model’s reasoning process. This transparency is crucial for debugging and improving model performance, as it allows us to pinpoint where errors occur in the reasoning path.
- Applicability across domains: While CoT is especially powerful in arithmetic reasoning, its principles can be applied to various other tasks. Commonsense reasoning, for instance, benefits from CoT by allowing models to connect seemingly unrelated pieces of knowledge through a logical thought process.
- Few-shot learning without the need for fine-tuning: CoT prompting is particularly useful in few-shot learning. Instead of needing vast amounts of data to train a model, we can prompt it with a few examples of CoT reasoning, and the model can generalize this approach to new tasks. This method is highly efficient because it avoids the costs associated with fine-tuning models on massive datasets.
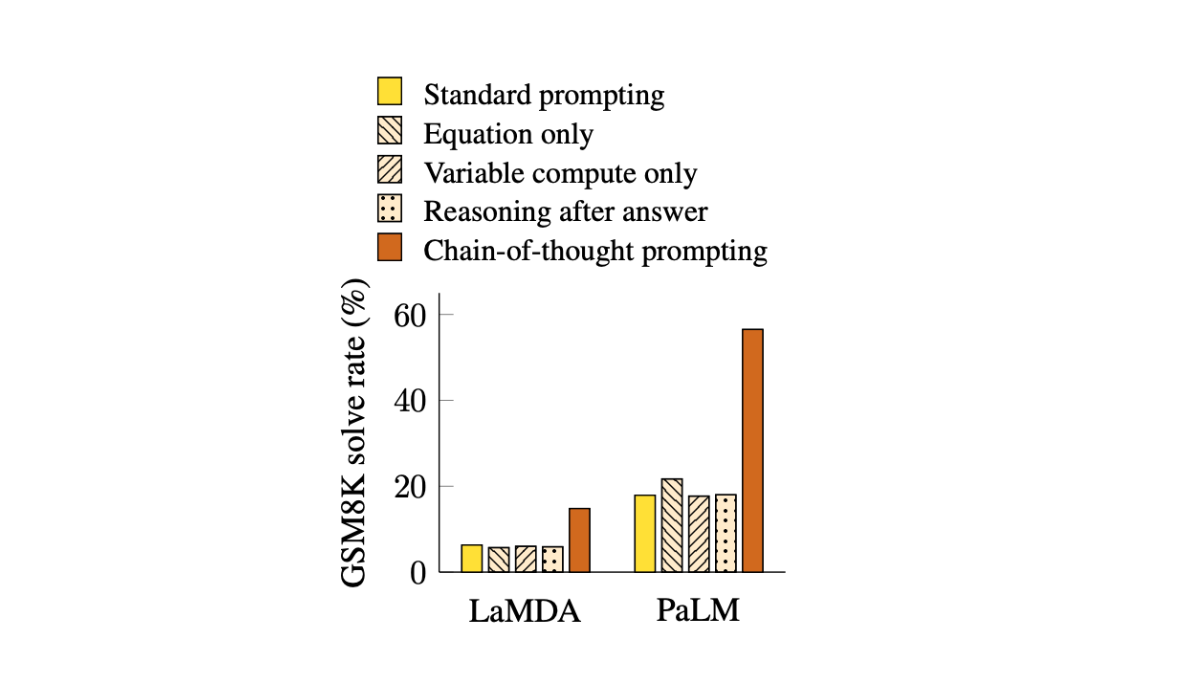
CoT in arithmetic and symbolic reasoning
Arithmetic reasoning—where models solve math word problems—has traditionally been a tough nut to crack for AI. While language models can often provide correct answers, they frequently fail to explain their reasoning, leaving users wondering how the solution was reached.
CoT prompting addresses this by forcing models to generate a reasoning chain that mirrors how humans approach the problem. For instance, instead of simply outputting the final answer, a CoT-enabled model will detail its intermediate calculations, making the process interpretable and trustworthy.
Similarly, symbolic reasoning, such as the task of concatenating letters from words, benefits from CoT.
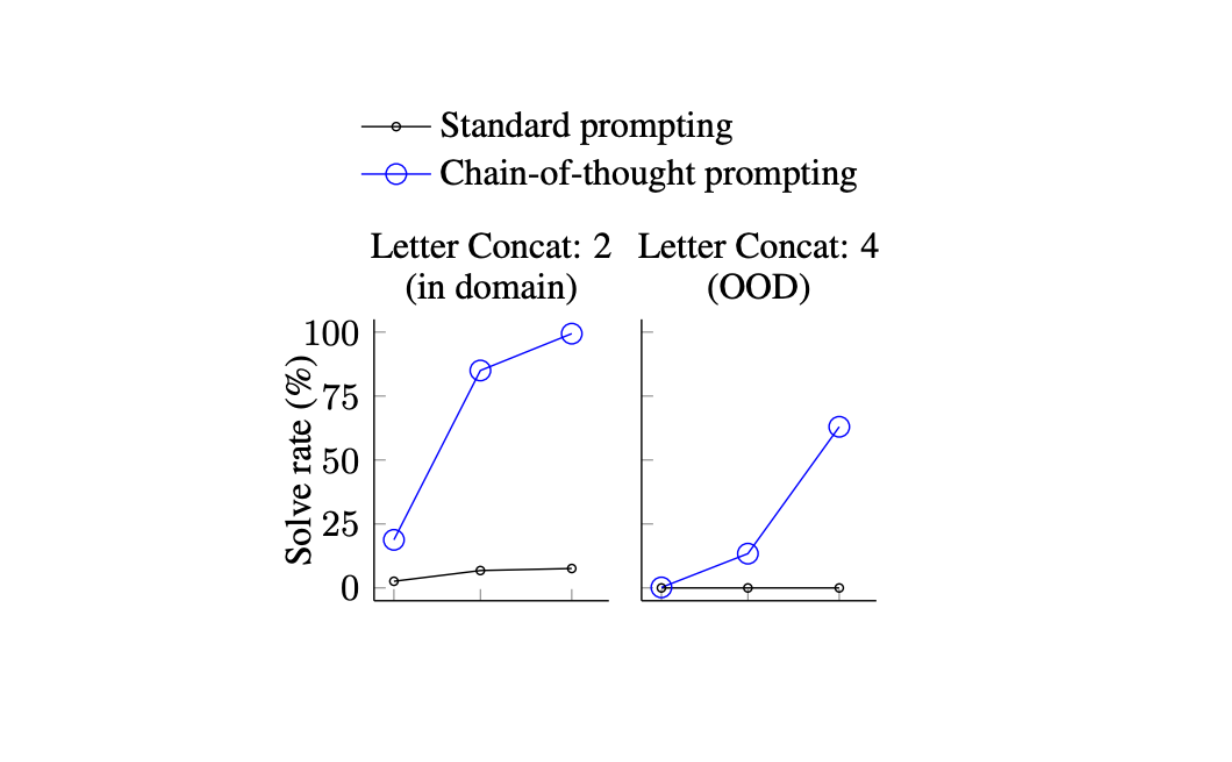
In such cases, models using CoT prompting have demonstrated the ability to generalize beyond the specific examples they’ve seen, handling even out-of-domain tasks that require abstract manipulation of symbols.
CoT in commonsense reasoning
One of the most exciting applications of CoT prompting is commonsense reasoning, an area where AI has historically struggled. Commonsense reasoning requires models to make inferences about the world based on incomplete information or implicit knowledge.
For example, when asked where someone might go if they want to be around other people, a CoT-prompted model would break down the possibilities (e.g., race tracks, deserts, apartments) and logically eliminate those that don’t make sense. This process mimics how humans would reason through the problem, leading to more accurate and reliable answers.
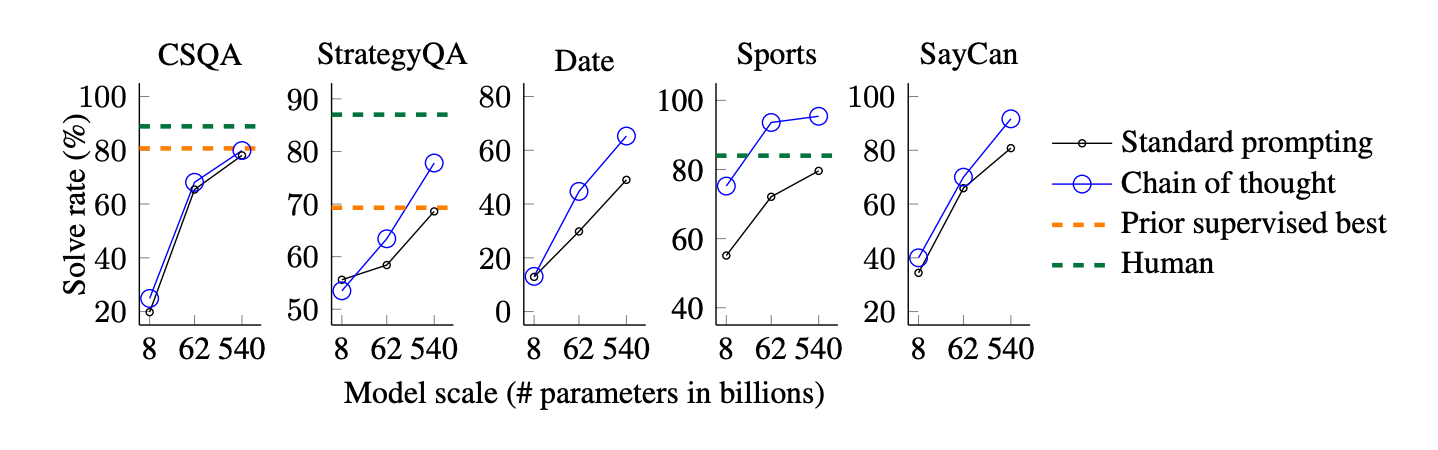
In a series of experiments, models like PaLM 540B, when using CoT prompting, outperformed baseline models on tasks like the CommonsenseQA benchmark. These results underscore the versatility of CoT across different reasoning domains.
Three key factors influencing CoT performance
The study identified three critical factors that systematically affect CoT performance:
- Probability: The likelihood of the task’s correct output has a significant impact on CoT performance. When the correct output is more probable, LLMs perform better. For instance, in the study, varying the probability of outputs in GPT-4 led to a significant shift in accuracy—from 26% to 70%.
- Memorization: LLMs often rely on what they have learned during pre-training. For tasks frequently encountered during pre-training, performance tends to be higher. For example, the rot-13 cipher (a commonly used shift cipher) shows a spike in accuracy due to its frequent appearance in online forums, illustrating that memorization plays a role in CoT performance.
- Noisy reasoning: As the number of intermediate reasoning steps increases, so does the likelihood of errors. This phenomenon, referred to as "noisy reasoning," shows that LLMs do not always execute flawless reasoning steps. The study found that the more complex the reasoning chain (e.g., with larger shifts in the cipher), the more likely it was that the model would make mistakes.
The middle ground: Reasoning and heuristics
The findings suggest that CoT prompting in LLMs reflects both memorization and probabilistic reasoning rather than pure symbolic reasoning. In other words, CoT prompting enables LLMs to adopt a noisy version of true reasoning, where errors become more frequent as task difficulty increases. This nuanced view supports the idea that while LLMs can exhibit some aspects of reasoning, they also rely heavily on heuristics and the statistical patterns learned during training.
For example, while GPT-4 could accurately decode simple ciphers with smaller shifts, it struggled with larger shifts unless they were commonly encountered (such as rot-13). Additionally, the model often relied on probabilistic reasoning, which would "self-correct" its final output to a more probable word even if the intermediate reasoning steps suggested otherwise.
Conclusion
In conclusion, Chain-of-Thought prompting demonstrates its strength, especially in large-scale language models like GPT and PaLM. By enabling stepwise reasoning, CoT significantly improves performance in complex tasks such as arithmetic reasoning, math word problems, and commonsense reasoning, as evidenced by its success on benchmarks like GSM8K. This technique not only outperforms traditional approaches but also highlights the probabilistic and heuristic nature of reasoning in LLMs.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your Gen AI application's performance with Maxim.


