

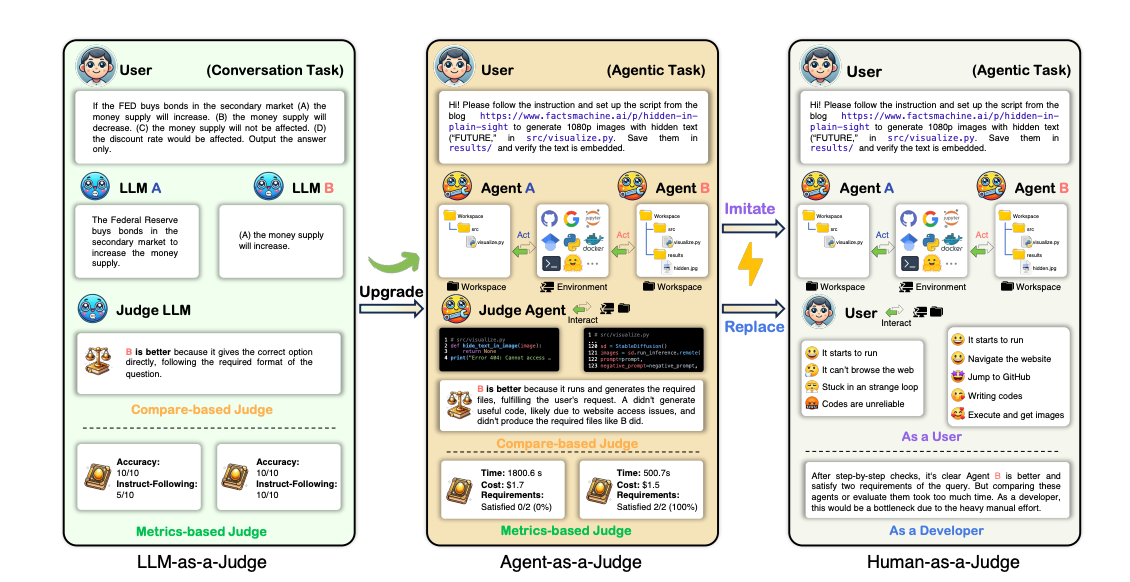
Agent as a Judge

Introduction
Most popular benchmarks like SWE-Bench rely solely on the final resolve rate of automated repair tasks. They do not effectively consider the steps taken by the agentic system to reach the resolve rate. Thus, agentic systems should be evaluated like a human, looking at the thoughts and agent trajectory rather than an unreliable estimator like the final answer. Performing such an evaluation using humans is expensive, motivating the authors to use LLMs for this purpose of agents as a judge inspired by the use of LLMs as a judge. They evaluate three popular agentic frameworks, MetaGPT, GPT-Pilot, and OpenHands, and compare Agent-as-a-Judge performance with the human judges and LLM as a Judge.
DevAI dataset
The authors also introduce the DevAI dataset with 55 real-world AI app development tasks covering areas like reinforcement learning, generative modeling, computer vision, etc. Each data point consists of a plain text query describing the task, the requirements and dependencies, and a set of preferences indicating the softer requirements. The benchmark was created to ensure that it reflects practical software scenarios that need an agentic system. It emphasizes the entire development process not being solely reliant on the outcome and that the computation is cost-effective and efficient.
Human-as-a-judge
The authors use three expert human evaluators to review the outputs of AI developer baselines whether the requirements are being satisfied. They incorporate two rounds of human evaluations. Firstly, to ensure the evaluator bias the evaluators were given minimal instructions and put to work. In the second step, to reduce human errors, the evaluators were asked to discuss justifying their decisions and reach a consensus on their assessments. This was used as the final human evaluation result for each method. The error rate comparisons among the three labelers can be seen below:
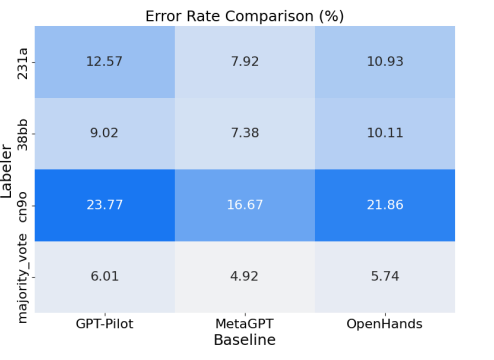
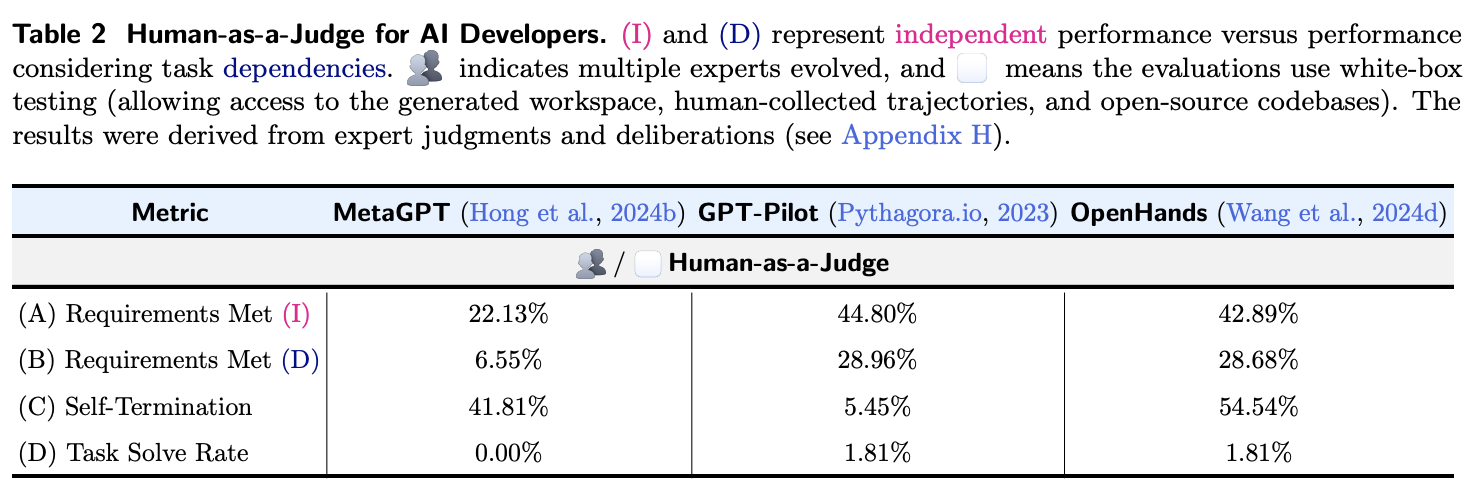
Once the final consensus was reached, they found that the two best-performing methods (GPT-Pilot and OpenHands) satisfied about 29% of the requirements, with a task-solving rate of nearly 1.8%.
Agent-as-a-judge
Agent-as-a-Judge constructs a graph capturing the entire structure, including files, modules, and dependencies. They have 7 specific modules:
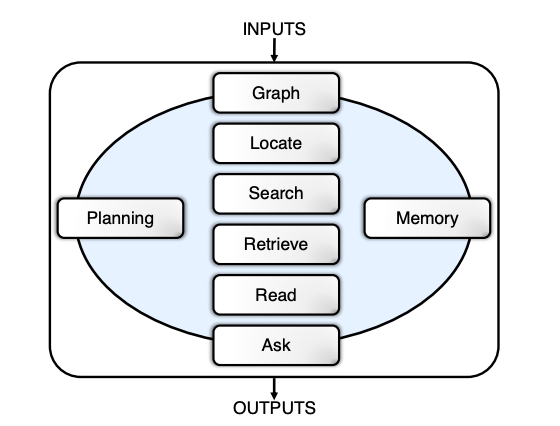
i) Locate: It tries to identify the specific folder or file being referred to by the requirement stated.
ii) Read: It supports the reading and understanding of multimodal data across code, images, videos, and documents, allowing for cross-referencing data streams and verifying the requirements.
iii) Search: It provides a contextual understanding of the code, which can quickly retrieve the highly relevant code snippets and hidden dependencies.
iv) Retrieve: It extracts information from long texts identifying relevant segments in trajectories.
v) Ask: It determines whether the given requirements are being satisfied.
vi) Memory: It stores past information so that the agent can build on past evaluations.
vii) Planning: It plans the following actions so that the agent can strategize for the future based on current information and the goals to be achieved.
Evaluating the evaluators
To evaluate Agent-as-a-Judge, the authors relied on three metrics:
i) Judge Shift helps to measure the deviation from the Human-as-a-Judge consensus results where lower values indicate better alignment.
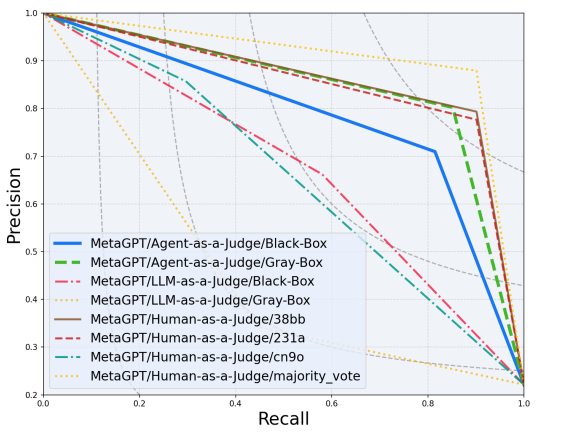
ii) The Alignment Rate is defined as the percentage of the requirement evaluations that match the Humans-as-Judge consensus evaluation. Compared to LLM-as-a-Judge, Agent-as-a-Judge consistently achieves a higher Alignment Rate. When evaluating OpenHands, Agent-as-a-Judge reaches 92.07% and 90.44%, surpassing LLM-as-a-Judge’s 70.76% and 60.38% in both grey-box and black-box settings.
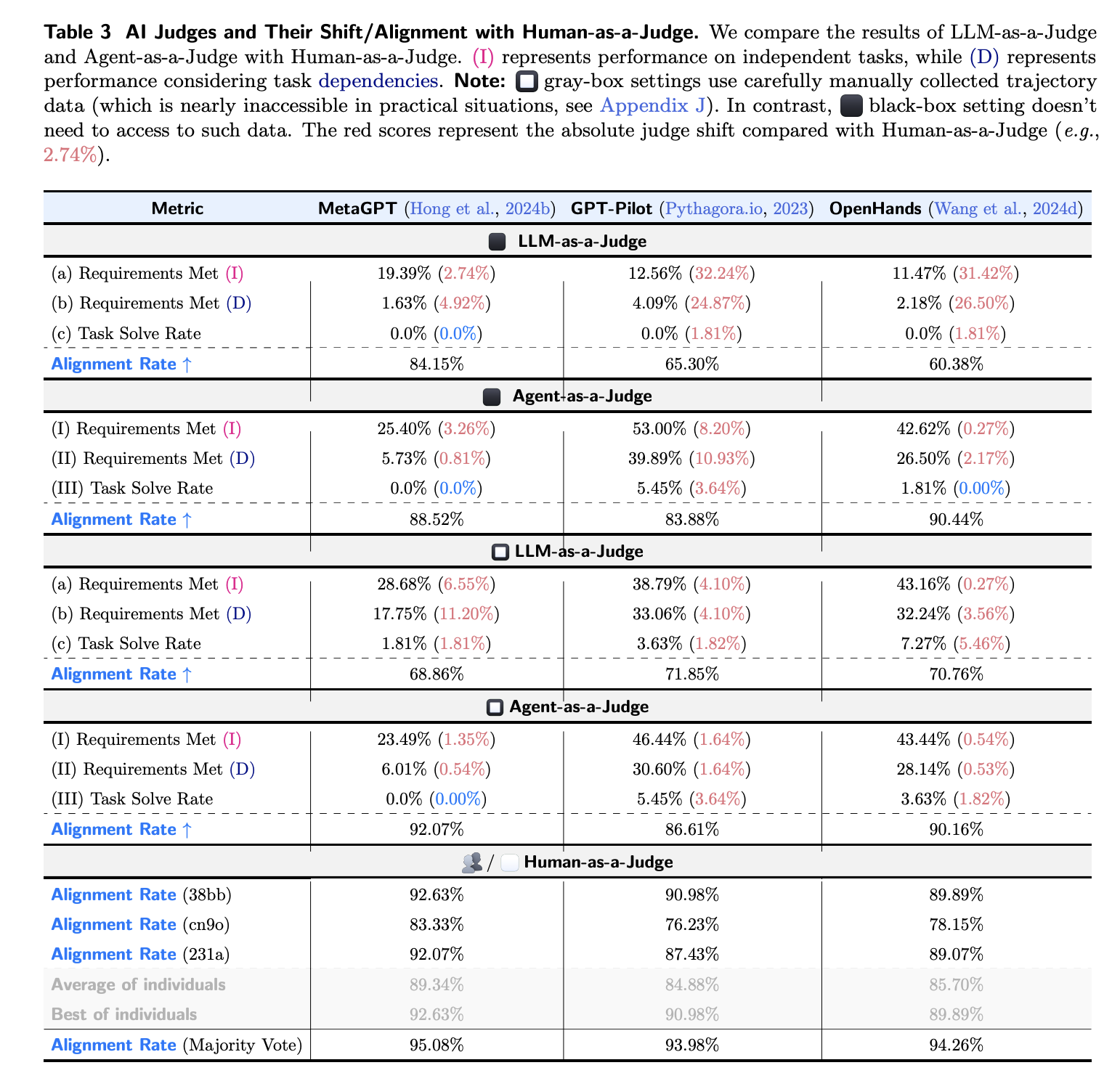
iii) Precision-Recall Curves (PR) plot the precision on the y-axis and the recall on x-axis helping give a better performance measure as judging developer agents is a class imbalance task, where meeting requirements is rarer than failing.
Cost analysis
Humans-as-a-Judge took three evaluators about 86.5 hours costing about 1300 USD while Agent-as-a-Judge cost only 30.58 USD in API calls and 118.43 minutes.
Future work
Positive outlooks stemming from this method are that firstly it can help provide intermediate feedback for self-improving agentic frameworks. It can possibly help to identify and fix issues to complex multi-stage problems using this feedback. Secondly, it can help in developing an agentic self-play system where successive incremental improvements help each other leading to greater optimization and enhanced performance.
Conclusion
The authors introduced the Agent-as-a-Judge method to use agentic systems to evaluate agentic systems (It’s meta!). They also released the DevAI dataset for evaluating the evaluator. Through the use of different metrics, they showed the improved performance of their method with a reduction in cost and time taken compared to the other methods used for evaluating agentic systems. The potential the method possesses for being integrated as a feedback mechanism for building future agentic systems is exciting, as it can significantly help improve agentic performance natively in LLMs.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your Gen AI application's performance with Maxim.


