

LongRAG

What is LongRAG? What's the buzz around this?
In this blog post, we are taking references from the LongRAG research paper to provide a detailed explanation of LongRAG.
LongRAG (Long Retrieval-Augmented Generation) is a framework that uses long-context language models to enhance traditional Retrieval-Augmented Generation (RAG) methods. In a traditional RAG framework, the retriever works with short retrieval units, such as 100-word paragraphs, which require searching through a large corpus to find relevant information. This can create an imbalance where the retriever has a heavy workload while the reader only needs to extract answers from these short units.
LongRAG addresses this imbalance by using longer retrieval units, significantly reducing the number of units the retriever has to search through. This new approach decreases the burden on the retriever and allows for better recall and overall performance. LongRAG then feeds the top retrieved long units (around 30,000 tokens) to a long-context language model to perform zero-shot answer extraction.
Problems with Traditional RAG
- Imbalanced Design:
- Heavy Retriever: The retriever must perform a lot of work because it must search numerous documents to find relevant information.
- Light Reader: Once the retriever has done its job, the reader's task is relatively straightforward, as it only needs to extract answers from the retrieved chunks. This imbalance places too much pressure on the retriever.
- High Retrieval Load:
- To achieve great performance, state-of-the-art RAG models must recall many such search units. For example, models like those by Izacard and Grave must retrieve the top 100 or even more units to have a meaningful context.
- Complex Re-Ranker: These models often require an additional complex re-ranking step to refine the selection of the most relevant chunks. This adds to the computational burden and complexity.
- Semantic Incompleteness:
- Short Retrieval Units: When the retrieval units are short (e.g., 100-word paragraphs), they can suffer from semantic incompleteness due to document truncation. This means that important context or information might be lost because it was cut off during chunking.
- Information Loss: The truncation and resulting loss of context can restrict the model's overall performance, as it might miss crucial details needed to generate accurate answers.
- Historical Context:
- The traditional design of the RAG framework was influenced by the limitations of NLP models at the time, which struggled to handle long contexts. This necessitated breaking documents into smaller chunks that the models could process effectively. However, for many RAG applications, it is very important to include Historical context as well, thereby further increasing data source sizes and retrieval units.
- Advances in Long-Context Models:
- Recent advancements in long-context language models now allow for processing much larger text inputs. Modern models can easily handle upwards of 128K tokens or even millions of tokens as input.
LongRAG vs Traditional RAG
To understand the differences between LongRAG and traditional Retrieval-Augmented Generation (RAG) methods, let's consider how each processes the vast information within Wikipedia.
Traditional RAG
Traditional RAG frameworks operate with short retrieval units, typically around 100-word paragraphs. When tasked with finding relevant information, the retriever must sift through a massive corpus comprising millions of these short units. This process can be likened to finding a needle in a haystack, where the retriever bears a heavy burden to locate the precise pieces of information. The reader's role is relatively straightforward, extracting answers from these short, retrieved units.
LongRAG
LongRAG revolutionizes this approach by processing Wikipedia into much larger units, each containing approximately 4,000 tokens. This makes the retrieval units 30 times longer than those used in traditional methods. By increasing the length of each unit, LongRAG dramatically reduces the number of units the retriever needs to scan—from 22 million short units to just 600,000 long units. This reduction lightens the retriever's workload, allowing it to operate more efficiently and effectively.
Increased Unit Size: The framework (LongRAG) increases the size of the units it processes from short segments (like 100-word paragraphs ~ 133 tokens) to much larger ones (4,000 tokens)
Reduced Total Units: By processing larger units, the total number of units on the Wikipedia dataset decreases dramatically. In the LongRAG paper, the authors mention how they got the total units down from 22 million (22M) in the case of traditional RAG to 600,000 (600K). This means there are fewer large chunks for the retriever to search through.
Lowering the Burden on the Retriever: With fewer, larger units to process, the retriever finds relevant information more easily. It doesn't have to sift through as many segments, which makes the retrieval process more efficient.
Improved Retrieval Scores:
- On the Natural Questions (NQ) dataset, the recall@1 score improved from 52% to 71%. This means the retriever can find the correct answer in the top result 71% of the time, up from 52%.
- On the HotpotQA (full-wiki) dataset, the recall@2 score improved from 47% to 72%. This means the retriever can find the correct answer within the top 2 results 72% of the time, up from 47%.
Performance Metrics (Exact Match, EM): This metric measures the percentage of answers that match the ground truth exactly.
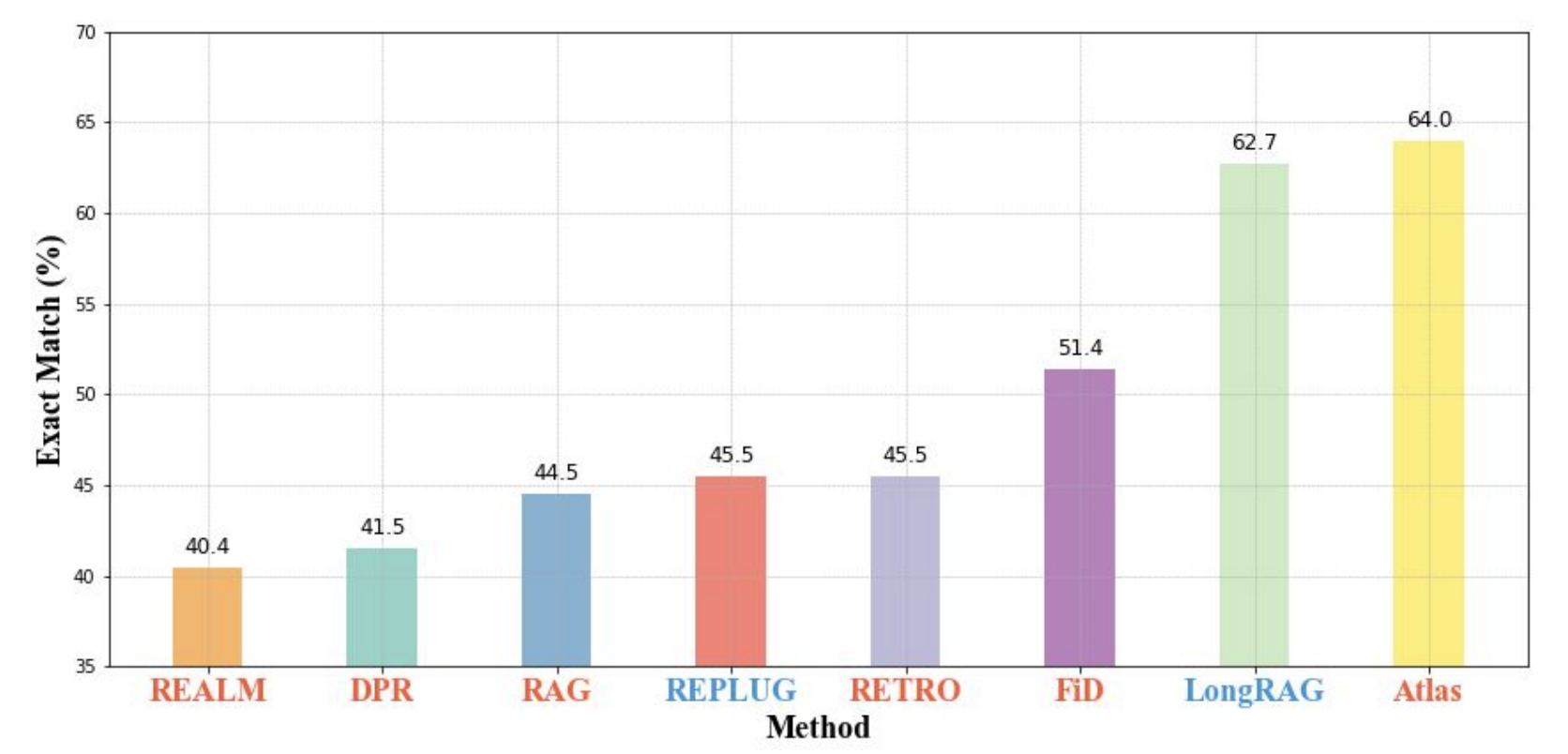
- On the Natural Questions (NQ) dataset, LongRAG achieves an EM score of 62.7%, which means that 62.7% of the answers it provides are exactly correct.
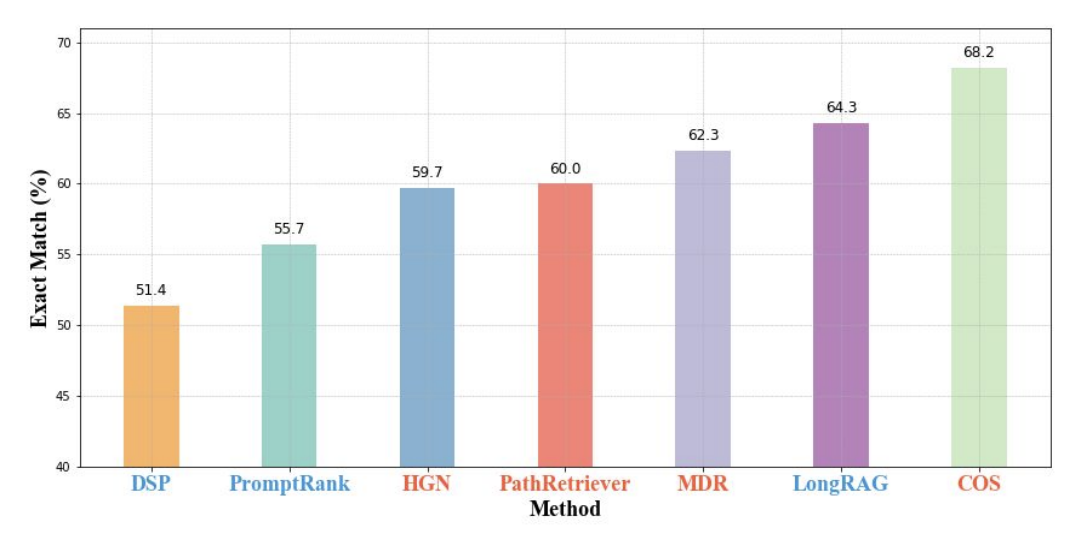
- On the HotpotQA (full-wiki) dataset, LongRAG achieves an EM score of 64.3%, which means that 64.3% of its answers are exactly correct.
LongRAG deep-dive:
LongRAG's framework leverages long-context language models and extended retrieval units to streamline the retrieval process, improve recall rates, and enhance the accuracy of generated answers. By incorporating LongRetriever and LongReader, this approach addresses the limitations of traditional RAG methods, making it a powerful tool for handling large corpora and complex information retrieval tasks.
How are the retrieval units made?
A function, G(C), is applied to the corpus ( C ) to create ( M ) retrieval units: ( G(C) = {g_1, g_2,..., g_M} ).
In the traditional RAG framework, each retrieval unit ( g ) is typically a short span of text split from the documents ( d ), containing 100 tokens. In our LongRAG framework, ( g ) can be as long as an entire document or even a group of documents.
Document Grouping:
- The documents are grouped based on their relationships. This grouping is done using hyperlinks embedded within each document, which indicate how the documents are related to each other.
- The output of this process of grouping related documents is a list of documents that are related to each other.
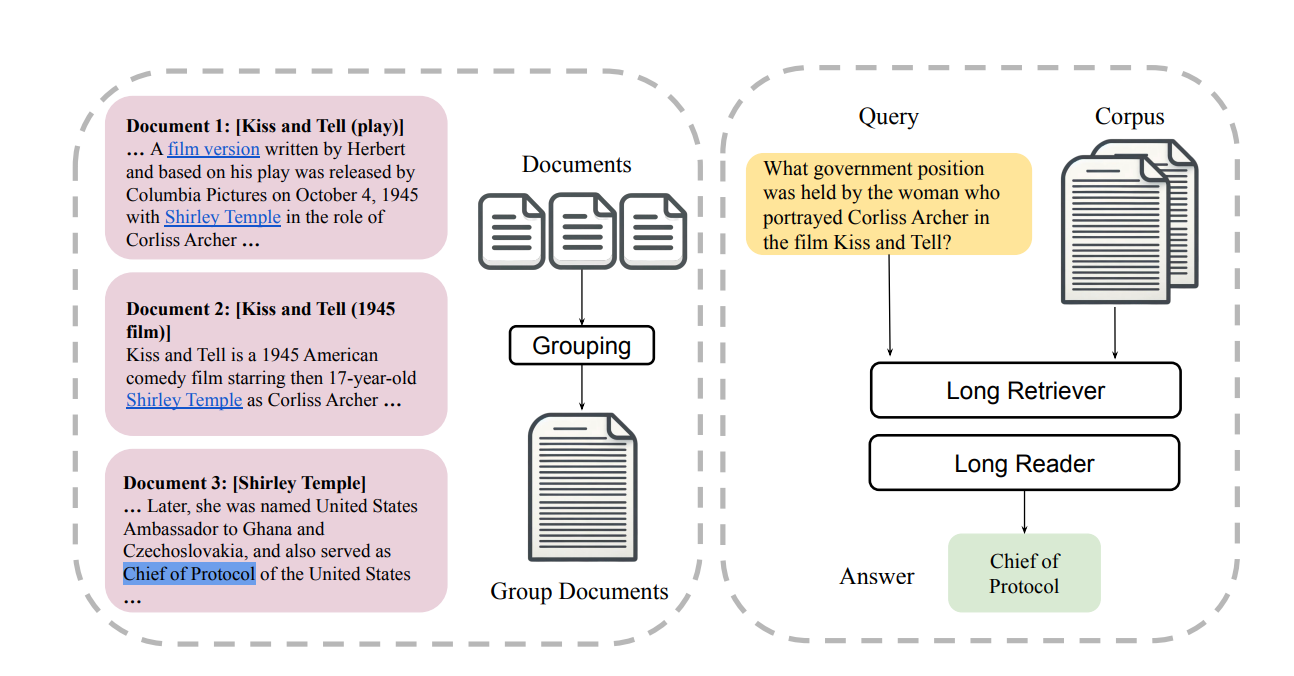
LongRetriever
LongRetriever is designed to process and retrieve information from larger, more contextually rich units. This innovation reduces the search burden, improves recall rates, and enhances the efficiency of the LongRAG framework, making it a powerful tool for handling extensive and complex information retrieval tasks.
What is the strategy behind selecting the retrieval units?
The goal is to perform a similarity search between a query (q) and retrieval units (g) using vector embeddings.
Vector Embedding:
- EQ(q): Represents the embedding of the input question q using the encoder EQ.
- EC(g): Represents the embedding of the retrieval unit g using the encoder EC.
Similarity Calculation: The similarity between the question q and the retrieval unit g is defined using the dot product of their embeddings.
sim(q, g) = EQ(q)^T . EC(g)
Here, ( EQ(q)^T ) denotes the transpose of the embedding vector EQ(q).
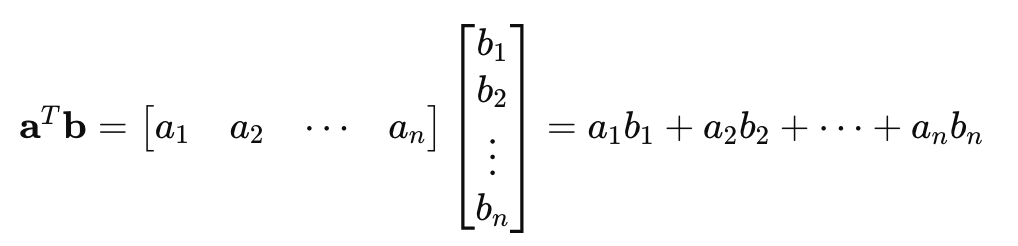
Taking the transpose of a vector and then performing the dot product with another vector is a standard operation that calculates the scalar projection of one vector onto another
Challenges with EC(g) in LongRAG Settings: In scenarios where the retrieval unit g is lengthy (as in LongRAG settings), directly computing the embedding EC(g) might be computationally intensive or impractical due to memory constraints.
Approximation Strategy: To address this, an approximation is used where the similarity score is approximated by maximizing over all possible chunks ( g' ⊆ g ):
sim(q, g) ≈ max (EQ(q)^T . EC( g')) , where g' ⊆ g
This involves breaking down the retrieval unit g into smaller chunks ( g' ) and computing the similarity score for each chunk.
Granularity Levels: Different levels of granularity can be considered for chunking, such as passage level, document level, or even the complete grouped document, depending on the application and efficiency requirements.
How are the top K retrieval units selected?
Concatenation of Top K Retrieval Units:
- After performing a similarity search, the top k retrieval units that are most similar to a given query are selected.
- These top k retrieval units are concatenated together to form a single long context, denoted as CF=Concat(g1,g2,…, gk).
- Here, ( g1,g2,…, gk) represent the individual retrieval units selected based on their similarity scores.
Impact of Retrieval Unit Size on k:
- The size of the retrieval unit (such as passage, document, or grouped documents) influences the selection of k:
- Passage: If the retrieval unit size is small, such as a passage, a larger value of k is typically used, approximately above 100. This means more passages (typically the top-scoring ones) are concatenated together.
- Document: For larger units like documents, k is reduced to around 10. This is because documents are longer and more comprehensive, so fewer top documents are concatenated.
- Grouped Documents: When retrieval units are grouped documents (collections of related documents), an even smaller value of k, usually 4 to 8, is sufficient. This reflects the higher granularity and comprehensiveness of grouped documents than individual documents.
Example Scenarios:
Scenario 1: If the retrieval system uses passages as units and retrieves the top 100 passages, CF would concatenate all these passages together.
Scenario 2: If documents are the retrieval units and the system retrieves the top 10 documents, CF would concatenate these 10 documents.
Scenario 3: For grouped documents where the system retrieves the top 4 to 8 groups, CF would concatenate the documents within these selected groups.
LongReader
The Long Reader component is designed to process and extract answers from long context inputs in the LongRAG framework.
How It operates?
Input Feeding:
- The related instruction i, question q, and the long retrieval result CF are fed into a large language model (LLM).
- This enables the LLM to reason over the long context and generate the final output.
Requirements for the LLM:
- The LLM used in the long reader must be capable of handling long contexts.
- It should not exhibit excessive position bias and should not overly favor information from certain input parts.
Selected LLMs:
- The chosen models for the Long Reader are Gemini1.5-Pro and GPT-4o (OpenAI, 2024).
- These models are selected for their strong ability to handle long context inputs.
Approaches for Different Context Lengths:
Short Contexts (< 1K tokens): For short contexts, the reader is instructed to directly extract the answer from the provided context retrieved from the corpus.
Long Contexts (> 4K tokens): For long contexts, using the same prompt as for short contexts (direct extraction) often leads to decreased performance. Instead, the effective approach is to use the LLM as a chat model:
- Step 1: Initially, the LLM outputs a long answer, typically spanning from a few words to a few sentences.
- Step 2: Then, the LLM is prompted to generate a short answer by extracting it from the initial long answer.
Conclusion
The LongRAG framework introduces an innovative approach to balancing the workload in RAG systems by leveraging longer retrieval units. This results in a smaller corpus, better recall, and maintained semantic integrity, ultimately enhancing the performance of question-answering tasks without additional training. LongRAG represents a significant step forward in the design of Retrieval-Augmented Generation systems.
You can test out your LongRAG on Maxim today. We support all long context Large Language Models.